Python ile Veri Aktarım Süreci Geliştirme
2021-01-19 Büşra Güner
Python ile Veri Aktarım Süreci Geliştirme
Çoğu veri aktarım sürecinde SQL, SSIS veya çeşitli ETL araçlarını kullanırken nereden çıktı bu Python? :)
Demeyin öyle! Çok daha temiz bir kod ve daha az geliştirme maliyeti ile istediğimiz veri aktarım işlemlerini Python ile yapabiliyoruz.
Şimdi birlikte Url bağlantısı ile birden fazla dosya indirme, döngü içerisinde “…tsv.gz” uzantılı dosyaları unzip etme ve aldığımız verileri SQL tablolarına aktaracağımız bir süreç geliştireceğiz.

Sürecin belli noktalarına farklı döngüsel fonksiyonlar eklenebilir. Ancak şimdilik amacım kolay anlaşılabilmesi ve kendi kod bloklarımıza entegre edebilmemiz olduğu için parçalara bölerek paylaşmak istiyorum.
1 - Kütüphaneleri import ederek başlıyoruz.
# Libraries
import re
from urllib import request
import gzip
import shutil
import requests
import pandas as pd
import pyodbc
import sqlalchemy
import urllib
from multiprocessing.pool import ThreadPool
2 - Url bağlantısı ile dosyayı download edip ardında “.gz” uzantılı dosyayı unzip eden fonksiyonu tanımlıyoruz. Kod arasında açıklamaları adım adım yorum satırlarına ekliyorum.
def download_url(url): # Download process print("downloading: ",url) file_title = re.split(pattern='/', string=url)[-1] urlrtv = request.urlretrieve(url=url, filename=file_title) # for ".tsv" to ".csv" title = re.split(pattern=r'\.tsv', string=file_title)[0] +".csv" # Unzip ".gz" file with gzip.open(file_title, 'rb') as f_in: with open(title, 'wb') as f_out: shutil.copyfileobj(f_in, f_out)
3 - Oluşturduğumuz fonksiyona göndereceğimiz Url bağlantılarını öncelikle bir list’e tanımlıyoruz. Veri setlerini aldığım bağlantıda toplam 7 dosya bulunuyor. Yazımızda iki dosya üzerinden örneklendireceğim. Ancak denemek isteyenler için diğer bağlantıları da değişken içerisinde bırakıyorum.
# URL List urls = ["https://datasets.imdbws.com/title.episode.tsv.gz" ,"https://datasets.imdbws.com/title.ratings.tsv.gz" #,"https://datasets.imdbws.com/title.akas.tsv.gz" #,"https://datasets.imdbws.com/title.basics.tsv.gz" #,"https://datasets.imdbws.com/title.crew.tsv.gz" #,"https://datasets.imdbws.com/title.principals.tsv.gz" #,"https://datasets.imdbws.com/name.basics.tsv.gz" ]
# Run 5 multiple threads. Each call will take the next element in urls list results = ThreadPool(5).imap_unordered(download_url, urls) for r in results: print(r)
4 - Dosyalarımızı indirdik, unzip ettik ve csv dönüşümlerini de gerçekleştirdik. Bundan sonraki adımsa, kolayca veriyi işleyebilmek ve SQL’e aktarabilmek için Data Frame’e çevirmek olacaktır.
# Read ".csv" file for Title Ratings title_ratings_data = pd.read_csv (‘title.ratings.csv’,sep=’\\t’,engine = ‘python’,na_values=[‘\\N’])
# Data to DataFrame title_ratings = pd.DataFrame(title_ratings_data, columns= ['tconst','averageRating','numVotes'])
# Read ".csv" file for Title Episode title_episode_data = pd.read_csv ('title.episode.csv',sep='\\t',engine = 'python',na_values=['\\N'])
# Data to DataFrame title_episode = pd.DataFrame(title_episode_data, columns= ['tconst','parentTconst','seasonNumber','episodeNumber'])
5 - Sırada ise Data Frame’lerde bulunan verimizi SQL tablolarına insert etmek var. Burada çok farklı yöntemlerle veri yazma işlemi gerçekleştirilebiliyor. Bunlardan birkaçını denedikten sonra, performans sonucu en iyi olan kod bloğunu tespit ediyoruz.
# Insert DataFrame to SQL Table for Title Ratings driver = ‘{ODBC Driver 17 for SQL Server}’ server = ‘(local)’ database = ‘MediumDS’ username = ‘medium’ password = ‘mediumds’ tbl = ‘title_ratings’
# Database connection params = ‘DRIVER=’+driver + ‘;SERVER=’+server + ‘;PORT=1433;DATABASE=’ + database + ‘;UID=’ + username + ‘;PWD=’ + password
cnxn = pyodbc.connect(params)
cursor = cnxn.cursor()
# Create SQL Table cursor.execute(‘DROP TABLE IF EXISTS dsf.title_ratings; CREATE TABLE dsf.title_ratings (tconst nvarchar(50), averageRating float, numVotes int)’) cnxn.commit()
db_params = urllib.parse.quote_plus(params)
engine = sqlalchemy.create_engine(“mssql+pyodbc:///?odbc_connect={}”.format(db_params))
from sqlalchemy import event
# The code below makes the data load much much faster @event.listens_for(engine, “before_cursor_execute”) def receive_before_cursor_execute( cnxn, cursor, statement, params, context, executemany ): if executemany: cursor.fast_executemany = True
# Insert Raw Data title_ratings.to_sql(tbl, engine, index=False, if_exists=”append”, schema=”dsf”)
# Insert DataFrame to SQL Table for Title Episode tbl = ‘title_episode’
cursor.execute(‘DROP TABLE IF EXISTS dsf.title_episode; CREATE TABLE dsf.title_episode (tconst nvarchar(50),parentTconst nvarchar(50),seasonNumber int,episodeNumber int)’)
cnxn.commit()
db_params = urllib.parse.quote_plus(params)
engine = sqlalchemy.create_engine(“mssql+pyodbc:///?odbc_connect={}”.format(db_params))
from sqlalchemy import event
@event.listens_for(engine, “before_cursor_execute”) def receive_before_cursor_execute( cnxn, cursor, statement, params, context, executemany ): if executemany: cursor.fast_executemany = True
title_episode.to_sql(tbl, engine, index=False, if_exists=”append”, schema=”dsf”)
# Delete DF
# title_episode = title_episode[0:0]
# title_episode_data = title_episode_data[0:0]
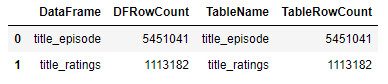
6 - Aktarım sırasında veri bazlı sorunlar yaşanabilir ya da aktarım yarıda kesilebilir. Hadi gelin Data Frame’lere aldığımız satır sayısı ile tablolara aktardığımız veri sayısının aynı olup olmadığını test edelim.
rowcounts = [["title_episode",len(title_episode)],["title_ratings",len(title_ratings)]]
rowcountsdf = pd.DataFrame(rowcounts,columns=['DataFrame','DFRowCount'])
SQL_RowCount = pd.read_sql_query(
'''SELECT [Tables].name AS [TableName],SUM([Partitions].[rows]) AS [TableRowCount]
FROM sys.tables AS [Tables]
JOIN sys.partitions AS [Partitions] ON [Tables].[object_id] = [Partitions].[object_id]AND [Partitions].index_id IN ( 0, 1 )
GROUP BY [Tables].name''', cnxn)
tablesdf = pd.DataFrame(SQL_RowCount,columns=['TableName','TableRowCount'])
pd.concat([rowcountsdf, tablesdf], axis=1, join="inner")
7 - Ve aslında tamamen obsesif yanımı temsil eden ve benim gibi “artık ihtiyaç olmayan dosyaları rafa kaldıran kişiler” için bu maddede ise indirdiğimiz ve aktarımını sağladığımız “.gz” ve “.csv” dosyalarının bir düzen içerisinde saklanması için “Backup” klasörüne aktarımını sağlıyoruz.
import shutil
original_csv = r’C:\Users\busra\Documents\Python Scripts\title.ratings.csv’
original_gz = r’C:\Users\busra\Documents\Python Scripts\title.ratings.tsv.gz’
target_csv = r’C:\Users\busra\Documents\Python Scripts\Backups\CSVs\title.ratings.csv’
target_gz = r’C:\Users\busra\Documents\Python Scripts\Backups\Gzs\title.ratings.tsv.gz’
shutil.move(original_csv,target_csv)
shutil.move(original_gz,target_gz)
Python üzerinde her zaman doğrudan bu süreci işletmeniz gerekmese de parça parça kendi veri aktarımı ya da ETL sürecinize entegre edebileceğiniz kod bloklarını görmüş olduk.